こんにちは、Progateの前田(@kzk_maeda)です。
Progateではエンジニアマネージャーとして働きながら、社外ではAWS Community BuildersやAWS Startup Community Core Memberとして活動もしております。
この記事はAWS Startup Community #6 のイベント開催レポートです。
当イベントは「LT 初心者大歓迎!はじめての LT すぺしゃる」と題打って、Startupで働くもののコミュニティでのLTにはあまり慣れていないようなエンジニアに集まってもらって、各社の技術的な話や社内で行っている勉強会の話などをしてもらいました。
記事の最後にイベントのアーカイブ動画もありますのでぜひご参照ください!
オープニング
オープニングはAWSの松田さんからコミュニティの紹介です。
AWS Startup Community では、AWS を利用するスタートアップ同士が、交流や知見の共有を通じて、スタートアップならではの悩みや課題を解消、そしてサポートできるコミュニティを目指しています。
また、コミュニティの中でスタートアップ企業の露出機会を提供することにより、企業名やプロダクトの知名度向上に寄与できれば嬉しいなと思っています。
つまり
スタートアップの、
スタートアップによる、
スタートアップのためのコミュニティです!!!
ぜひみなさん奮ってご参加ください。
続いて連絡事項です。
連絡事項1:次回イベントページの公開
次回のMeetupイベントページを公開しております!
aws-startup-community.connpass.com
「あつまれ!大企業/SIer 出身スタートアップエンジニア!!」と題して、大企業やSIer出身で、現在スタートアップで活躍されている人にLTしていただくイベントを企画し、公開しております。
登壇枠はもう埋まってしまっておりますが、奮ってご参加ください!
続いてはイベントセッションについてです。
DevAx::connect はじめました
一つ目のセッションはAWSの金森さんから、DevAx::connectの紹介です。
DevAxとは、来たるクラウドネイティブ時代に備えて、クラウドを使ったモダンなシステム開発のパターン・プラクティスを学びながら、よりクラウドを活用したDevelopmentの支援を行う目的でスタートした活動です。
その中でもDevAx::connectはクラウドネイティブなデザインに関するWebinarです。
第一回は「イベント駆動」を題材に複数回に渡ってセッションが行われています。

AWSを活用したイベント駆動アーキテクチャでのシステム設計に於いて、メッセージブローカーや状態管理、テスト、冪等性など考えないといけないことが多く、ベストプラクティスもよくわからない世界なので、こういった丁寧なWebinarがあると世の中の開発者のイベント駆動アーキテクト能力が向上されていい未来が訪れそうだなと思いました。
(この後、過去10時間分のセッションを10分でまとめてくださっていますが、文章にしても伝わらないと思ったのでぜひ動画を見てください!)
EC2 & 手動デプロイから ECS & CodePipeline に変えてみた
二つ目のセッションは、株式会社AMDlabの柴田さん(@shibattyo2)からCI/CD周りの話です。
Beforeのデプロイ手法、身に覚えのある方たくさんいらっしゃるんじゃないでしょうか・・
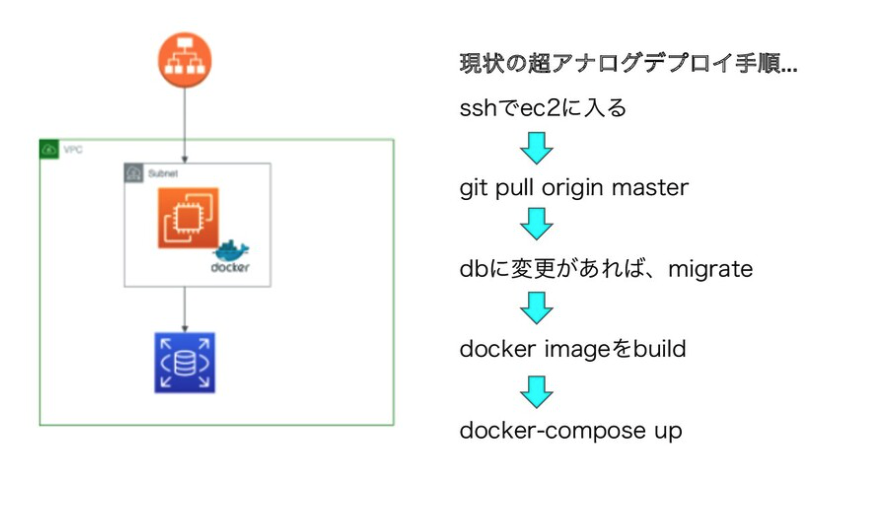
ここから、まずコンピューティングリソースをECS(Fargate)にリプレイスするための道のりをお話いただきました。
aws-cliでの操作やvolume共有で詰まったところなど赤裸々に語ってくれていて、共感された方も多いかなと思います。
次に、CI/CDのパイプライン作りにCodePipelineを導入した話をしていただきました。
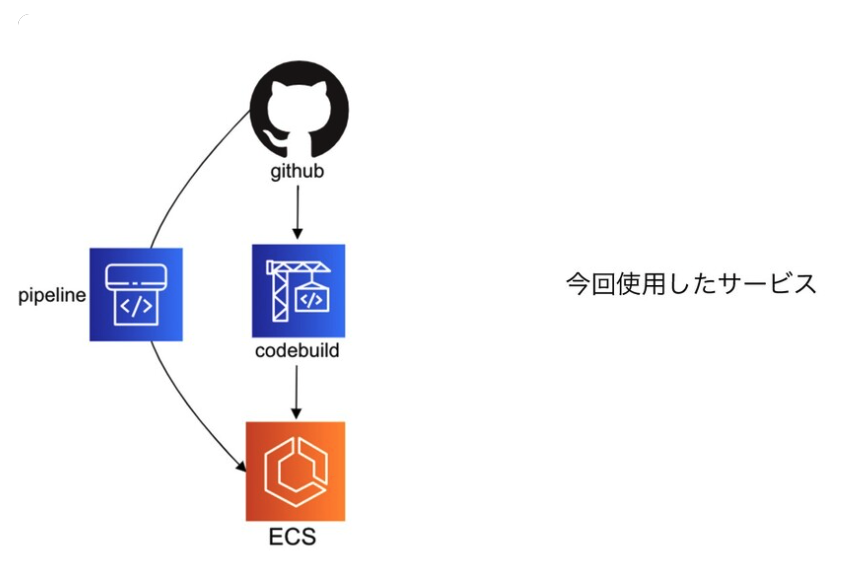
CodePipelineといえば、所謂Code兄弟を用いたPipeline実装のためのサービスと思われがちですが、実はSourceRepositoryとしてGithubが利用できたり、 Amazon ECS に直接Deployできるなどの柔軟性を持ったサービスで、この話をされているとき、Twitterでも「知らなかった」などの驚きの声がちらほらと見られました。
こういった知見が共有できる場として、コミュニティやLTは非常にいいですね!
最終的には手動デプロイの運用負荷が減ったことや、AWSを触るのがより楽しくなったという感想で締めていただきました。
Q&A
Q: CI/CDを導入して、体感どれくらいDevEx改善しましたか?
- A: 数値的な表現となるとちょっと難しいのですが、アプリケーション開発の終盤で導入しても、sshコマンド打つ→docker-composeコマンドを打つ、migrationをかけるなど、また、sshコマンド忘れたから検索するなどの細々した心理的な負担が減ったので、開発の序盤から導入したら、もっと円滑に開発できたなぁと感じています!
Q: codepipelineは手動で作られたのでしょうか?複数アカウント(dev, staging, prodなど)にパイプラインを作るときcodepipeline自体をCDKやcloudformationとかで作るべきか悩んでいます。
- A: awsのコンソール画面から作りました!私自身、CDKやcloudformationを触ったことがないので、慣れた方法で良いのかなと思うのですが、元々環境の基盤ができているのであれば(例えば、dev, staging, prodそれぞれのECSのタスク稼働まで)、awsのコンソール画面から画面通りに進めば、割と簡単にできてしまうので、最初はコンソール画面からやってみると良いかと思います!
Q: 変更前後でデプロイ時間がどれくらい変わったか気になりました。
- A: 時間的にはsshでEC2に入って、docker-composeコマンドを打つまでおおよそ5分程ですかね?その時間がデプロイのする度に都度かかってしまうので、その分が丸々減った印象です!ただ、もっと開発の序盤に導入してたら、より円滑に開発できたと感じています!
Q: 規模感が話の中にあると良かったような気がします
- A: 次回発表の機会があれば、もう少し具体的にどれぐらいの規模で、どれぐらいの改善があったかを話したいです!
RDB ばっかり使ってきたエンジニアが DynamoDB を使って感じたこと
三つ目のセッションは、株式会社オークンの笹川さん、竹内さんから、社内の勉強会でDynamoDBを使ってみた所感についての話です。
社内の勉強会で、使ったことのない技術に触れてみようという意気込みがあるのがまず素晴らしいですよね!
普段はRDBMSを使うことが多いので、NoSQLに入門するためにDynamoDBについて二人で勉強されたそうです。
AWS公式のチュートリアルを一通りやって、基本的なところはわかったものの、徐々に発展的な内容に入っていくとなかなか詰まったそうで・・
最終的にたどり着いた結論はこちらだそうです。

このセッションを聴いていて、「ハンズオンを何度も何度も繰り返して手を動かすことで、DynamoDBの輪郭が見えてきた」というお二人の感想がめちゃくちゃいいと思いました。
Q&A
Q: DynamoDBを使って何かサービス作ってみましょう!
- A: もちろん作ります!次回登壇する際には作ったプロダクトも含めてご紹介したいと思います!
Q: 感じてどうしたのか、どうしていこうと考えたのかがあると良かったような気がします
- A: エンジニアとして、自分たちが常に最善の一手をうつ必要がある中で、未知の領域に飛び込み、少し学ぶだけでも駒を増やせることをひしひしと感じました。 そのため、AWSのサービスに限らず「未知」だから使えないのではなく、「未知」だから使ってみたい(=ハンズオンをしてみたい)と強く思うようになりました! DynamoDBに限らず他のサービスも自分たちの血肉にしていきます!
Identity Lifecycleのつらみを解決するサービスを作った
四つ目のセッションは、株式会社OwNの粕尾さん(@Flog_kt)から、ご自身が代表を勤められている会社で作っているID Providerサービスについての話です。
Identity Lifecycle / ID管理機能を新規に実装する時に、検討すべき項目は多岐にわたります。
また、SNSアカウントによるSSOの選択肢も増えてきており、簡単にID管理機能を導入できるサービス(IDaaS)も登場してきていますが、サービス開発者的な視点で見ると、SSOされたアカウントから求める情報を取得することが出来ないという課題感もあります。
そこで、OwN Authという新しいID管理サービスを開発したそうです!
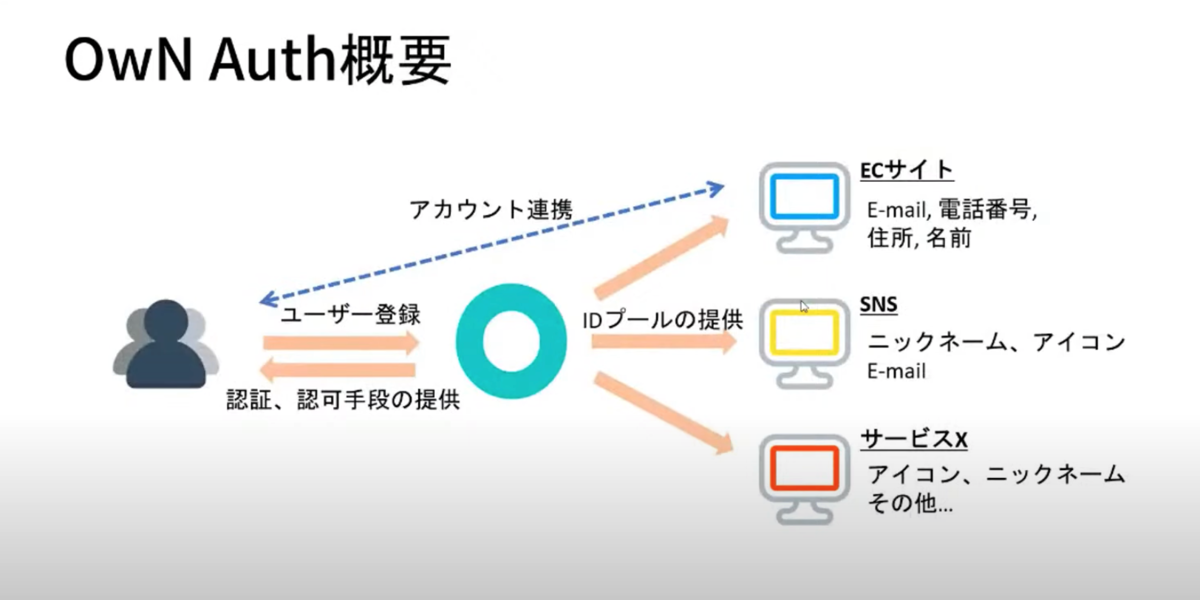
OwN Authでは、ID Provider側で不足している情報の取得を吸収してくれ、一度登録した情報は次回以降使い回すことが可能だそうです。
Own Authはテストユーザーを募集していて、マサカリを待っているそうなのでサービスに興味がある方は是非利用してみてください!

Q&A
Q: OwN Authはクライアント(サービス利用側)が追加で必要な個人情報を登録しておく必要があって、サービス側はOwN AuthとID連携する実装を入れる必要がある、というイメージですか?
- A: はい、その通りです! あらかじめサービス側にOwN AuthとのID連携機能を実装しておく必要があります。 ユーザーは既にOwNに登録している場合、簡単にサービスとID連携(ユーザー登録)が行えるようになっています。 また、OwNに登録していない場合には、連携時にユーザー登録を行うことができます。(この機能はまだ実装中です...)
Q: サービスAとBが OwN Auth で連携しているとして、サービスAで住所を入れるとサービスBが OwN Auth に対して claim で住所を要求してきたら、ユーザー側に許可を求めた上でサービスBに入力フリーで住所がわたる、ってイメージなのかな?
- A: はい、その通りです! 一度入力した情報をOwN Authがプールすることで、以降すべてのサービスでプールされた情報を使いまわすことができます。 また、情報の参照元が1つになることで、住所変更時等の対応も非常に簡単になります!
Q: 『OAuth徹底入門』は買った方がよいですか?
- A: OAuth徹底入門も大変良い書籍なのでオススメですが、個人的にはAuth屋さんの"雰囲気OAuth本"を強くお勧めします! 私の場合、雰囲気OAuth本 -> RFC -> OAuth徹底入門の流れで勉強しました。
Redshift ノードタイプを RA3 へ移行する際の苦労話
五つ目のセッションは、TVISION INSIGHTS株式会社の片岡さん(@motoy3d)から、Redshiftの運用知見についての話です。
TVの視聴データをRedshiftに格納して、分析アプリケーションから参照する用途で利用されているそうです。 また、データ量が大きいため、Node側に格納させると容量オーバーになるため、Redshift Spectrumを活用しているそうなのですが、データサイズの肥大化に比例してクエリが遅くなる問題が発生したとのことでした。
そこで、Redshiftのノードタイプを第3世代にあげて、ベンチマークをとって比較してみた結果が下記です。

なんとなく新しい世代を採用したり、スケールアップしたりして対策するのではなく、そこからちゃんとベンチマーク取るのがエンジニアリングって感じでいいですね。
また、最近GAになったマテリアライズドビュー機能に関しても検証中だそうで、結果が気になるところです!
Q&A
Q: 第2世代のクラスタって22ノードだったので実は全CPU数では減ってます?
- A: LTではCPUのみへの言及でしたが、メモリ、IOも影響するかと思います。 また、スライス数もノードごとに違いますが、Spectrumのパフォーマンスにスライス数が大きく影響しているようです。 https://aws.amazon.com/jp/blogs/news/10-best-practices-for-amazon-redshift-spectrum/ https://twitter.com/xerespm/status/1413118305401851915?s=20
Q: 今100億行のデータから抽出したViewを運用されているという話でしたが、データマートを個別に作らない理由は何かありますか??
- A: データマートは作っていて使用していますが、今回のケースでは業務用件的にローデータを使用する必要がある部分がありました。
イベント動画アーカイブ
ご紹介したイベントの様子は下記の動画からも参照できますので、ぜひご覧になってください!