はじめに
データ戦略を担当している@aaaanwzです。
Progateではデータ基盤にユーザーの皆様の利用状況を保管し、プロダクトをより良いものにしていくための分析に活用させて頂いています。
一例として、各レッスンのページをめくった時刻のデータがあります。
sample.user_page_history
| timestamp | user | lesson_name | page_num |
|---|---|---|---|
| 2022-09-20 00:00:00 | にんじゃわんこ | 学習レッスン HTML & CSS 初級編 | 1 |
| 2022-09-20 00:01:00 | にんじゃわんこ | 学習レッスン HTML & CSS 初級編 | 2 |
| 2022-09-20 00:02:00 | ひつじ仙人 | 道場レッスン HTML & CSS 上級編 | 12 |
今回はこのデータを軸にユーザーの方々の「学習習慣」というふわっとした要素を定量化してみたいと思います。
全体の傾向を見る
ある程度以上の学習を行なっているユーザーに注目したいため、以降注釈がない限りは個人で有料会員プランに加入されているユーザーを集計対象とします。
テーブルやSQLは説明用に架空のもの(文法はBigQuery準拠)を用いますが、集計結果は実際のデータに基づいています。
初めに全体の傾向を知るため、レッスンを問わず時間帯毎にページがどれくらいめくられているかを見てみます。
この時、仕事・学校などは学習を行う時間帯に大きな影響を与えるかもしれません。
祝日に関しては一旦置いておいて、月〜金曜日と土日を別々に集計してみます。
▼SQL (クリックで開く)
SELECT is_holiday, hour, IF(is_holiday, degree/2, degree/5) AS degree_per_day FROM( SELECT EXTRACT( DAYOFWEEK ROM DATE(timestamp,"Asia/Tokyo") ) IN (1,7) AS is_holiday, EXTRACT( HOUR FROM DATETIME(timestamp, "Asia/Tokyo") ) hour, COUNT(*) AS degree FROM sample.user_page_history GROUP BY hour, is_holiday )

統計量で見ると、意外と月〜金と土日で活動量(めくられたページ数の総量)に大きな変化はありませんでした。
ぱっと見てわかる事といえば11時・16時・22時に活動量のピークがあります。
皆が皆11時と16時と22時に学習をするわけでは当然なく、今見えているのは別々の習慣を持った集団の行動を重ね合わせた結果であるはずです。
もし学習習慣ごとに集団を分離できれば何か新しい発見があるかもしれません。
機械学習で学習習慣ごとにユーザーを分類する
データを分類ということで、機械学習における教師なし学習、いわゆるクラスタリングを試みてみましょう。
そのためにはユーザー1人ごとに学習習慣を表現するベクトルが必要です。
学習データのイメージとしてはこんな感じになります。
| user | hour_0 | hour_1 | ... | hour_22 | hour_23 |
|---|---|---|---|---|---|
| にんじゃわんこ | 0.1 | 0.05 | ... | 0.02 | 0.03 |
| ひつじ仙人 | 0.0 | 0.2 | ... | 0.01 | 0.04 |
hour_0は0時、hour_23は23時の活動量を表します。先程のグラフより、平日・休日は区別しない事にします。
中の値は (この時間帯にめくった全ページ数)/(このユーザーがめくった全ページ数)と正規化することでヘビーユーザーとライトユーザーの重みを統一できそうです。
つまり学習させるデータは ユーザーのProgateにおける全学習時間のうち、この時間帯が占める割合 をパラメータとする24次元のベクトルです。
あまりスマートではないですがPIVOT句を使ったSQLで上記のデータを作ります。 長いSQLかつ今後何度も使うのでビューにしておきます。
▼SQL (クリックで開く)
CREATE OR REPLACE VIEW sample.user_study_time_distribution AS( SELECT a.user_id, IFNULL(hour_0,0)/total AS hour_0, IFNULL(hour_1,0)/total AS hour_1, # 中略 IFNULL(hour_22,0)/total AS hour_22, IFNULL(hour_23,0)/total AS hour_23, FROM sample.user_page_history, PIVOT ( COUNT(*) hour FOR EXTRACT(HOUR FROM DATETIME(timestamp, "Asia/Tokyo")) IN (0,1,2, #中略 22,23) ) a JOIN ( SELECT user_id, COUNT(*) total FROM sample.user_page_history GROUP BY user_id ) b ON a.user_id = b.user_id )
さて、データが用意できたところでいよいよモデルを作成します。 折角のBigQueryですのでBigQuery MLを使います。
CREATE MODEL sample.study_time_clustering OPTIONS(model_type='kmeans') AS SELECT * EXCEPT(user) FROM sample.user_study_time_distribution
モデルはk平均法、クラスタ数は指定せずにBQMLに任せてみます。 Progateの本番データでは4epochで学習が完了し、クラスタ数は5になりました。
以下のクエリでユーザーがどのクラスタに属するのかを見ることができます。
SELECT user, CENTROID_ID FROM ML.PREDICT(MODEL sample.study_time_clustering, ( SELECT * FROM sample.user_study_time_distribution))
| user | CENTROID_ID |
|---|---|
| にんじゃわんこ | 1 |
| ひつじ仙人 | 2 |
CENTROIDは学習習慣ベクトルの重心、つまりそのユーザーが属するクラスタを意味します。
クラスタ毎の学習習慣の可視化
さて、全体の傾向を見る セクションで使ったSQLに先ほどのCENTROID_IDをJOINすればいよいよクラスタ毎に分離された学習習慣が見られるはずです。
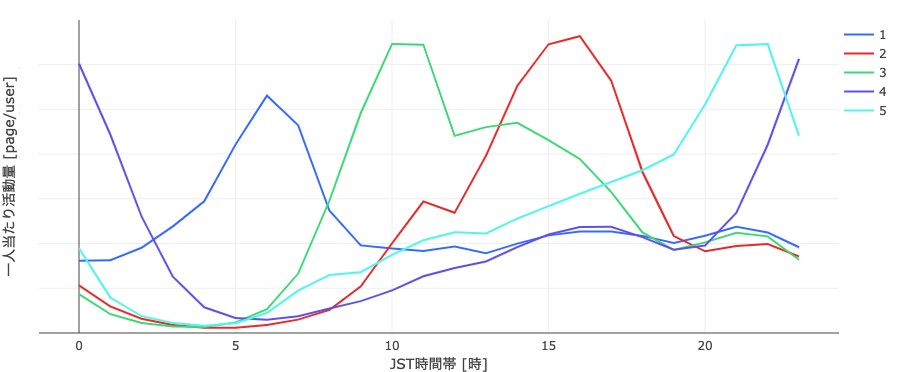
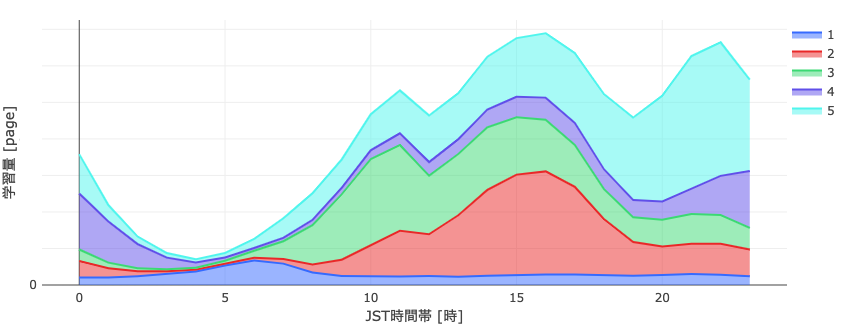
うまくいったようです! 3つのピークがあるグラフだったので3つにクラスタリングされるかと思いましたが、少数ながらも深夜0時ごろに活発なクラスタ、朝6時ごろに活発なクラスタが存在していたようです。
それぞれのクラスタの活動量は所定の時間帯を中心とした山なりの分布をしており、最初に見ていたものはこれらの重ね合わせだったという事です。
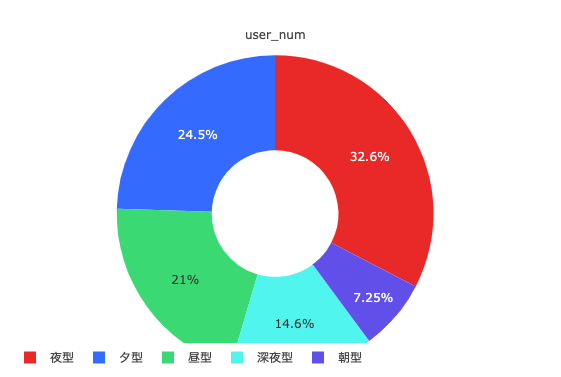
便宜上、以降は先程のCENTROID_IDをアクティブな時間帯毎にそれぞれ朝型(6時ごろ)・昼型(10~11時)・夕型(15~16時)・夜型(21~22時)・深夜型(23~24時)と呼ぶことにします。
ユーザー数の割合は以下の通りでした。
クラスタ毎の学習ペースの違い
いよいよ本題です。上述の学習習慣クラスタごとに他の様々なデータを集計します。
全てのクラスタに数万〜数十万人が含まれているため基本的に統計誤差は無視します。
まずは各クラスタ毎にProgateのアクティブ日数/1日あたりのめくったページ数/完了レッスン数の違いを見てみます。 それぞれの数値は下限がゼロで上限は無しなので、平均値よりも中央値ないし四分位数を評価するのが妥当でしょう。
厳密に言えばアクティブ日数の上限はProgateのサービス開始からなので7年ですが、標準偏差がとても大きいのでやはり平均値を使うのは微妙そうです。
アクティブ日数
| クラスタ | 75%tile | 50%tile | 25%tile |
|---|---|---|---|
| 朝型 | 36 | 20 | 10 |
| 昼型 | 33 | 18 | 9 |
| 夕型 | 29 | 16 | 9 |
| 夜型 | 35 | 19 | 11 |
| 深夜型 | 32 | 18 | 10 |
多いクラスタと少ないクラスタで2割近い大きな差がありました。 朝型・夜型のユーザーはアクティブ日数が多い傾向がありそうです。
一日あたりのめくったページ数
| クラスタ | 75%tile | 50%tile | 25%tile |
|---|---|---|---|
| 朝型 | 14.0 | 9.6 | 6.7 |
| 昼型 | 16.2 | 10.9 | 7.3 |
| 夕型 | 15.9 | 11.0 | 7.6 |
| 夜型 | 13.9 | 9.6 | 6.7 |
| 深夜型 | 13.6 | 9.3 | 6.4 |
こちらも2割弱の差が見られます。 昼型・夕型のユーザーは1日あたりの学習量が多い傾向がありそうです。
クラスタ毎のユーザー属性の違い
学習ペースの傾向が明らかになったところで、次はそれぞれのクラスタに含まれるユーザーの属性を推定してみます。
先日実施させていただいたアンケートの回答内容とその人の学習習慣の間に関係があるのか、有意水準5%のカイ二乗検定を行います。
Google Colab環境(Jupyter Notebook)でPythonを用います。
▼Notebook (クリックで開く)
from google.colab import auth
auth.authenticate_user()
print('Authenticated')
Authenticated
%%bigquery --project myproject df
SELECT
user,
CENTROID_ID,
current_job,
study_purpose,
future_study_plan
FROM
ML.PREDICT(MODEL sample.study_time_clustering,
(
SELECT
*
FROM
sample.user_study_time_distribution)) a
JOIN
sample.progate_survey b
ON
a.email = b.email
df
| user | CENTROID_ID | current_job | study_purpose | future_study_plan |
|---|---|---|---|---|
| にんじゃわんこ | 1 | 学生 | 今の仕事や学校でプログラミングの知識を活かすため | Progateで自分のペースで学習したい |
| ひつじ仙人 | 2 | その他 | 趣味・教養として興味があるため | Progateで自分のペースで学習したい |
import pandas as pd
import scipy.stats
actual = pd.crosstab(df.CENTROID_ID, df.current_job)
_, p, _, expected = scipy.stats.chi2_contingency(actual)
print("p = %(p)s" %locals() )
if p < 0.05:
print("職業で学習習慣に有意差あり")
print(actual)
print(expected)
else:
print("職業で学習習慣に有意差なし")
職業
p≒0.01となり、職業と学習習慣は独立ではないと言えそうです。
観測度数と期待度数の差を見るに、
- 学生は朝型が少なく昼型・深夜型が多い
- 社会人は夜型が多い
- その他の人は夕型が多く夜型は少ない
何となく直感に近い結果ですね。
学習している目的
p≒0.02となり、学習目的と学習習慣は独立ではないと言えそうです。
- 「現職または学校に活かすため」の方は朝・昼・夕が多く、夜型が少ない
- 「副業のため」の方は朝型が多く、昼型が少ない
- 「趣味・教養」の方は深夜型が少ない
仕事のために学習されている方は朝活をしている傾向があるのかもしれませんね。
今後の学習予定
p≒0.23となり、今後の学習予定と学習習慣は独立であると言えそうです。
まとめ
| クラスタ | 特徴 |
|---|---|
| 朝型 | ・アクティブ日数が多い ・学生が少ない ・現職または学校に活かすための人、副業のための人が多い |
| 昼型 | ・一日あたりの学習量が多い ・学生が多い ・現職または学校に活かすための人が多く、副業のための人が少ない |
| 夕型 | ・一日あたりの学習量が多い ・職業:その他が多い ・現職または学校に活かすための人が多い |
| 夜型 | ・アクティブ日数が多い ・社会人が多く、職業:その他が少ない |
| 深夜型 | ・学生が多い ・趣味や教養のための人が少ない |
おわりに
今回はBigQuery MLを用いてユーザーをアクティブな時間帯ごとにクラスタリングすることで、「学習習慣」という新たな切り口を作り出しました。 その学習習慣がレッスンの進め方やアンケートの回答と関係があるかをPythonでカイ2乗検定し、結果として学習ペース・職業・学習目的と関係がありそうで、今後の学習予定とは関係が無さそうであることがわかりました。
今回はアンケートの回答に伴うバイアスや要素間の因果関係を考慮していませんが、「機械学習でProgateユーザーの学習習慣を定量評価する」という主題から逸れてくるため割愛させて頂きます。
Progateは「誰もがプログラミングで可能性を広げられる世界をつくる」というビジョンを一緒に追求できる仲間を募集しています。
www.recruit.prog-8.com