Progateでエンジニアをしている山﨑です。本記事では弊社でよりデータドリブンな改善を進めていくために、サービス内でのユーザーの行動をログとして記録する仕組みを構築した事例を紹介いたします。
要旨
先に今回の取り組んだ内容を簡単にまとめます。
- リレーショナルデータベースに永続化されないデータをログとして残すことで、今まで取得できなかったデータを取得可能にした
- データ収集にはFluentd, AWS Kinesis Data Firehose, S3, Lambda等のサービスを使用してパイプラインを構築した
- BIツールであるRedashからデータ分析を可能にした
データ分析の課題
従来の運用
弊社ではメインサービス(以下Progate)を構成するためのデータを基本的にリレーショナルデータベースに保存しています。リレーショナルデータベースに保存されたデータは日時で実行されるバッチによってダンプされ、そのダンプデータに対してSQLをかけることでデータ分析を行ってきました。以下データ分析の例。
- 国ごとの課金ユーザー数の合計
- ユーザーがどの順番で演習を開始しているか
- 新規登録から1日後にどのくらい演習をクリアしているか
従来の運用の課題
リレーショナルデータベースのテーブルはアプリケーションに最適な設計がされているため、このデータを使って分析を行う場合以下のような課題がありました。
- データ分析の都合上永続化されて欲しいレコードが更新または破棄されてしまうことがある、その結果需要はあるが算出できない指標がある
- 高度な分析をしようとすると多くのテーブルを結合する必要があり、分析のオペレーションの負荷が高い (特に弊社ではエンジニア以外の人も活発にSQLを書いてデータ分析をしているため)
対応
方針
これらの課題を解決するためにリレーショナルデータベースとは別の、分析に最適化された基盤を構築してデータを蓄積していくことにしました。Progateのバックエンドで定義されているビジネスロジック(例えば、ユーザーの新規登録、課金、演習の開始など)をイベントとして定義し、そのイベントの処理が完了した結果をリレーショナルデータベースに保存するだけではなく分析に最適化した形で新しいデータ基盤にも保存することにしました。新しいデータ基盤に蓄積されるデータは更新、削除されることがないためデータの永続性も担保されます。
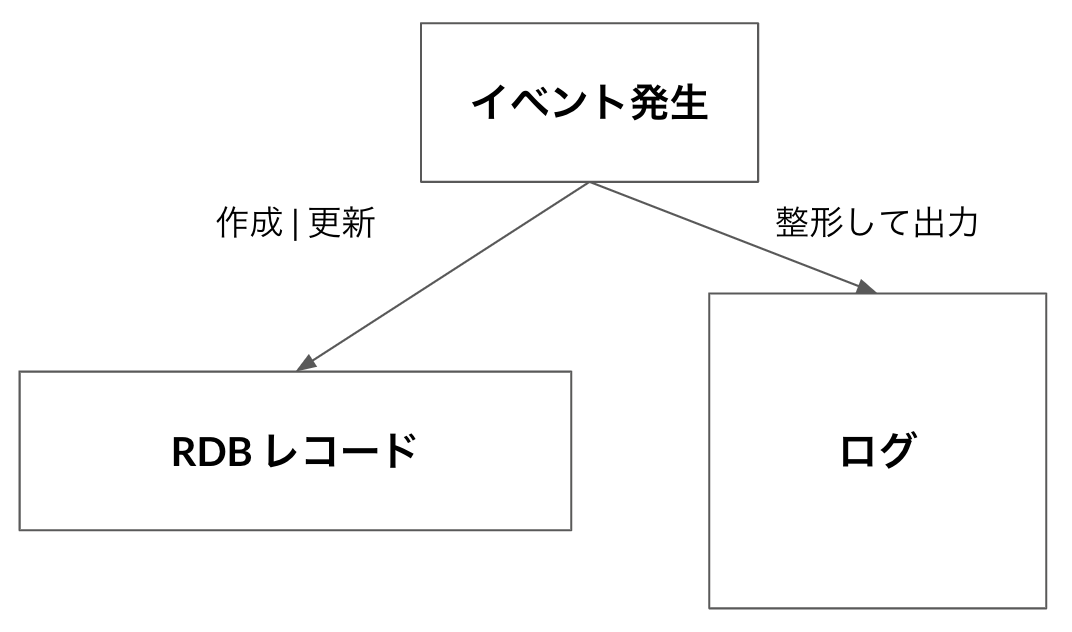
実装

構成のポイント
前述の通り弊社ではすでに多くの人がRedashを使った分析に慣れているため、新しい基盤もAthenaを経由してRedashからクエリをかけられることを前提にした構成になっています。
また、Kinesis Data FirehoseにLambda関数を登録しストリーミングしたデータを加工した上でS3に保存することも可能ですが、データの量の制約や異常検知の仕組みなどの導入のしやすさの観点からストーリミングしたデータを一度S3に保存した上でLambdaで処理をするという構成を採用しました。
イベントがデータとして蓄積される流れ
ログの出力 (構成図中①)
まずProgateのバックエンド内でイベントが起きた時に専用のログファイルにJSON形式のログを出力します。ProgateのバックエンドはRailsで動いているため、Ruby標準のLoggerクラスをラップした専用のLoggerクラスを作成し、RailsのModel内でイベントが発生した時にそのクラスに定義されたメソッドを呼び出すことでログを出力します。
ログの形式
実際に出力されるログはこのようなイメージです。
# ユーザーが新規登録した時に出力されるログのイメージ
{
"id": "a4a3dcb1-45a9-4791-8006-0d60eac42306",
"date":"2021-09-16T05:57:27Z",
"type":"user_registration",
"user_id":1,
"locale":"ja",
"country_code":"JP",
...
"params": {
"provider": "twitter",
...
}
}
イベントごとに一意なtypeを割り当てます。JSONの1階層目では全てのtype共通で取得したいデータを保持し、params内にネストされた部分でイベントごとに異なるデータを保持します。この例ではユーザーがどのOAuthプロバイダーを経由して新規登録したかをイベント固有の情報として保持しています。
ログのストリーミング (構成図中②)
ログファイルに出力されたログfluentdが収集してKinesis Data Firehoseにストリーミングします。収集されたログは一旦そのままの状態でS3に保存されます。
データの加工 (構成図中③)
S3へのputObjectをトリガーにLambdaが起動し以下の簡単な処理を行います。
- イベントのtypeごとによる分類 (ログはProgateが動いているインスタンスごと1つのファイル出力されるため、様々なイベントが混在した状態でストリーミングされます。)
- ログを1階層に戻す処理
これらの処理を経てログはイベントのtypeとApache Hive形式のパーティションを切った別のバケットに再度保存されます。typeごとにパーティションを切ることでクエリ効率の向上を狙っています。
# 最終的にS3に保存されるログファイルのキーのイメージ /user_registration/year=2021/month=09/day=16/hour=00/log.json
外部テーブル作成 (構成図中 ④)
S3に保存されたデータにクエリをかけることができるようにAthenaでCREATE EXTERNAL TABLEを実行して外部テーブルを作成します。外部テーブルを作成するためのDDLはAthena NamedQueryとしてterraformで管理しています。
パーティション管理
パーティション管理にはGlue Data Catalogなどでメタデータを管理する方法が一般的かと思いますが、今回はAthenaのPartition Projection機能を使用しました。Athenaがクエリを実行する際にパーティションの情報をAPIから取得する代わりに、あらかじめ設定された情報をもとにインメモリで計算を行います。この機能を使うと主に以下の2つのメリットがあります。
- パーティションの情報を取得するAPIコールをしない分、クエリの高速化が狙える (特にパーティションが細かく管理されている場合)
- パーティションの管理コストが低い (メタデータで管理している場合、Glue Crawlerなどを定期的に実行してメタデータをアップデートする必要がある)
まとめ
Progateのバックエンドで発生するイベントをログとして記録することで、今まで把握することができなかった指標の算出や、ユーザーの動きをデータとして可視化できたことがこの仕組みを構築した一番の成果だと考えています。また、精度の高い分析を行うには大量のデータを集める必要がありますが、今回はデータベースではなくS3という比較的安価なオブジェクトストレージにログとしてデータを残すことで長期的な管理コストや運用コストの削減につながる考えています。
最後までお読み頂きありがとうございます。