はじめまして、Progateの村山です。
本記事はProgateAdventCalendarの2日目の記事です。
普段はSREチームでProgateの開発や運用を支える仕事をしております。Progateには今年の7月に入社しました。前職はElixirやk8sなどを使ったWebアプリケーションの開発や運用をしていました。ProgateにElixirのコースを作るのがちょっとした野望です。
本稿ではサービスや開発のモニタリングについて紹介しようと思います。
モニタリングとは
モニタリングは日本語で監視と言い、主にサービスの障害検知や可用性向上のために利用されています。ここで紹介するモニタリングは大きく2種類に分類したいと思います。
1つ目は死活監視するためのモニタリングで、サービスやアプリケーションの可用性監視し、必要に応じてフェイルオーバーさせたりアラートを飛ばして開発者へと共有します。
2つ目はメトリクスのモニタリングです。サービスやサーバ、ミドルウェアなどのパラメータや状態を定期的に観測し、限界値などによってオートスケールさせたり、閾値を設けてアラートを飛ばして注意を促すことに利用されます。メトリクス監視は時系列データとして保存することで、季節要因のパフォーマンスを観測したり、限界値を計測するのにも利用されます。
何故モニタリングをするか
モニタリングをすることで自動で障害を検出したりサービスを復旧する事ができます。障害というと東京証券取引所の株式売買システムが停止したのが記憶に新しいですが、こちらも障害を早急に検出できたので、一時的に取引を止めるという判断を事前にすることができました。もし障害検知が遅れたり障害が起きてるにも関わらず取引を始めていたら今回以上の混乱をもたらしたことでしょう。
またモニタリングをしておくことで過去に起きた季節要因によるイベントなどに対する準備をすることができます。例えばソーシャルゲームを運用しているのであれば、前回の大型イベントではサーバのリソースを9割使っていたので、次回の大型イベントではユーザが1.5倍に増えていると予想される場合、耐えきれないことが推測できます。なので、事前にスケールアップの準備する、みたいなことを判断することができます。
他にもサービスや開発の健康状態を事前にメトリクスとして取得しておくことで、チームの客観的な評価をすることが出来ます。前職ではPRの数やIssueの数、AWSの費用(前月差)、Rollbarのエラー件数、デプロイの数などをGrafanaのダッシュボードで管理していました。またビジネス指標をダッシュボードとして定期観測しておくことで、見るべき指標を開発チーム内で示すことができます。また、サービスのKPIを取得するBIツールなどもモニタリングの一種と考えられます。
モニタリングサンプル
モニタリングツールはDataDogやNewRelicなどのクラウドサービスを使うのが主流ですが、今回は私が前職で使ってた無料で使えるGrafanaとPrometheusを紹介します。
GitHub - kdoam/monitoring: Sample code for monitoring, grafana and prometheus
これは私が個人的に公開しているモニタリングのサンプルで、Dockerをインストールしていれば簡単に立ち上げることが出来ます。
アーキテクチャ
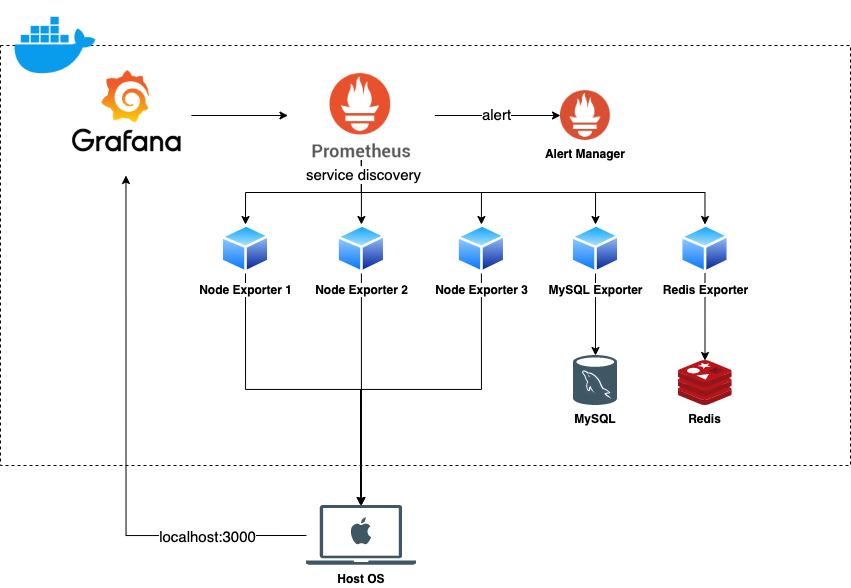
Docker composeで起動すると、Grafanaが立ち上がりデータソースとしてPrometheusが指定され、ホストOSのメトリクスや並列して立ち上がっているMySQLやRedisのメトリクスを収集するようになります。
Grafanaは指定したデータソースのメトリクスやログをダッシュボードとして表示するための可視化ツールです。データソースにはPrometheus以外にもGraphiteやCloudWatch、MySQLなどのRDBにも利用できます。またGrafana自体にもアラートを飛ばす機能がありますが本アーキテクチャではPrometheusのエコシステムであるAlertmanagerを使っています。
Prometheusは監視をするためのソフトウェアで、実質的にはメトリクスを記録するための時系列データベースとその監視のためのエコシステム群です。監視ツールとしては珍しいPull型のアーキテクチャを採用しており、HTTPのAPIをExporter(メトリクスを収集するエージェント)にリクエストして自身のデータベースに保存します。Exporterはリクエストを受けるとそのタイミングのメトリクスが表示されるような仕組みです。
Exporterの検出にはサービスディスカバリを使うことが出来ます。サービスディスカバリにはEC2、k8s、consulやYAMLなど、様々なツールを使うことが出来ます。
また、Prometheusはルールに基づいてしきい値が発火するとAlertmangerにPushリクエストを飛ばします。Alertmanagerは設定に基づいて、SlackやPagerDutyなどのWebhookを叩くことが可能です。
Prometheusの全体のアーキテクチャに関しては公式ドキュメントがとてもわかり易いのでご参考ください。
サンプルの起動方法
ローカル環境にgit cloneして、 docker-compose upをするだけです。
$ git clone git@github.com:oppai/monitoring
$ cd monitoring
$ docker-compose up -d
localhost:3000 にGrafanaがバインドされているのでブラウザで開くことでアクセスが出来ます。IDとパスワードは admin / admin です。
ダッシュボードの紹介
私がよく使うダッシュボードを紹介します。
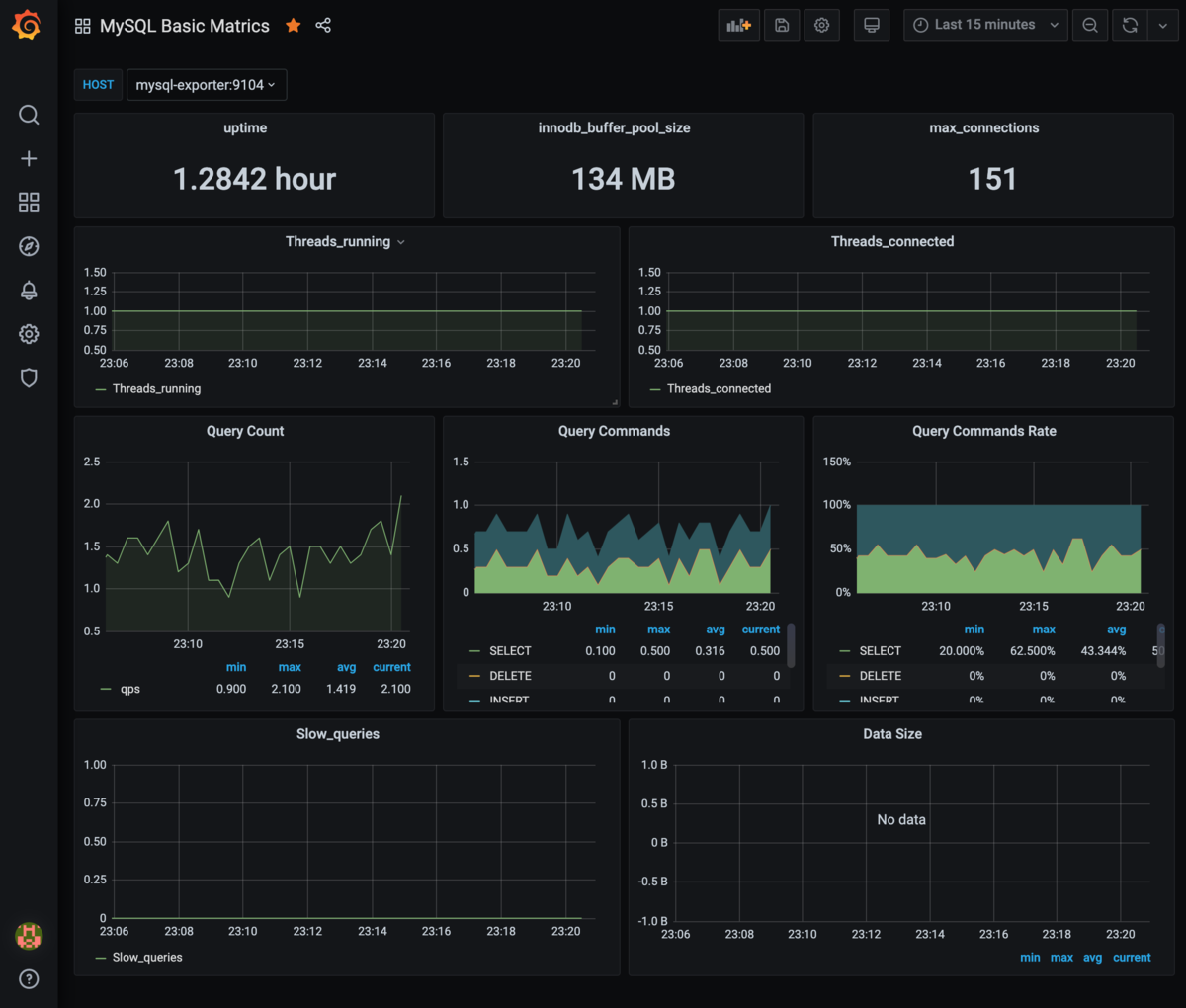
これはMySQLのメトリクスを収集するためのダッシュボードで、Connection数やQPS、SlowQueryなどを表示しています。またテーブル毎のレコード数などを表示するのをおすすめします。MySQLのメトリクスはperconaが提供してるダッシュボード(percona/grafana-dashboards)を参考にして作りました。
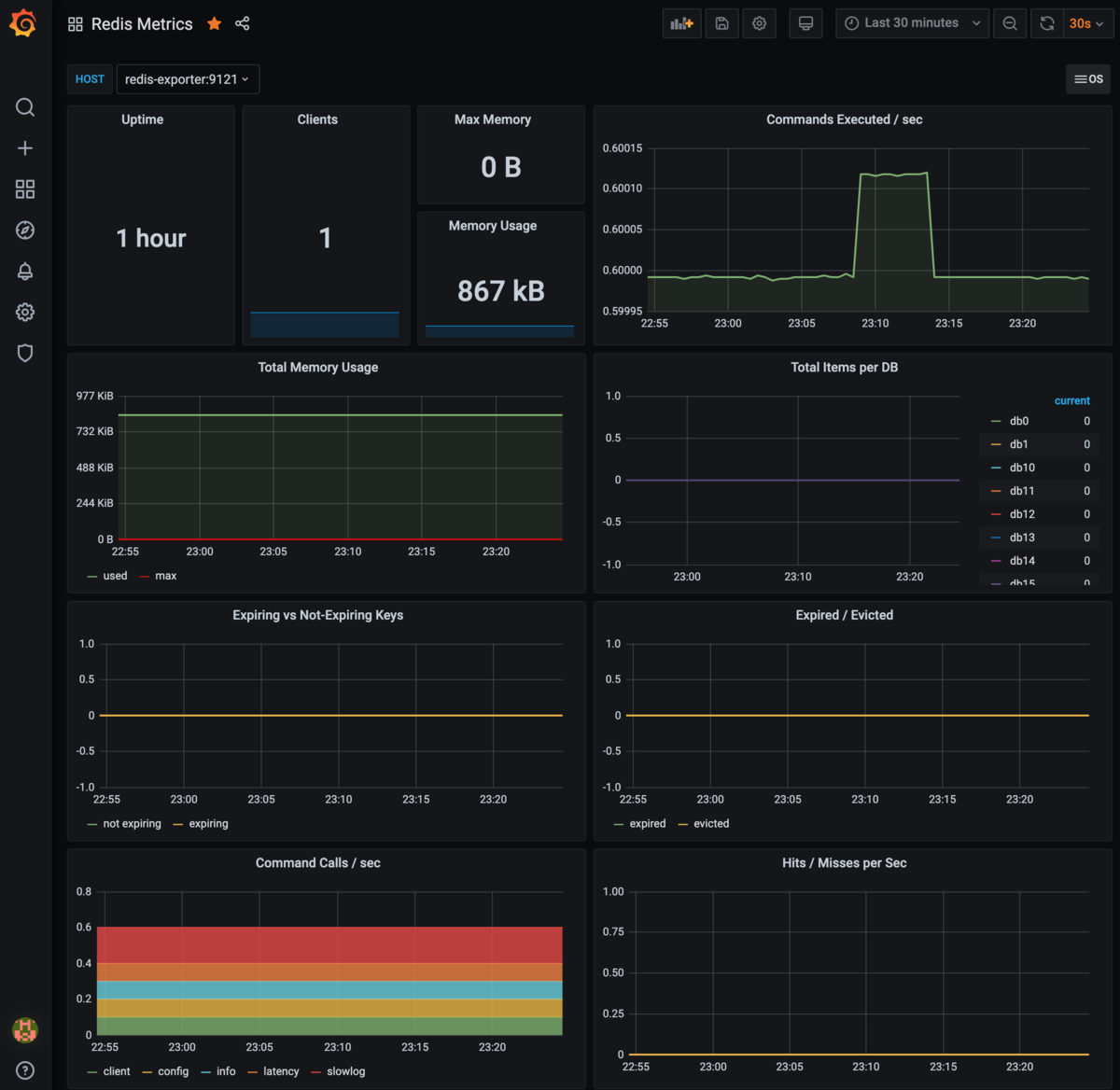
これはRedisのダッシュボードです。CommandsExcuted数やEviction数などを見ておくと良いです。
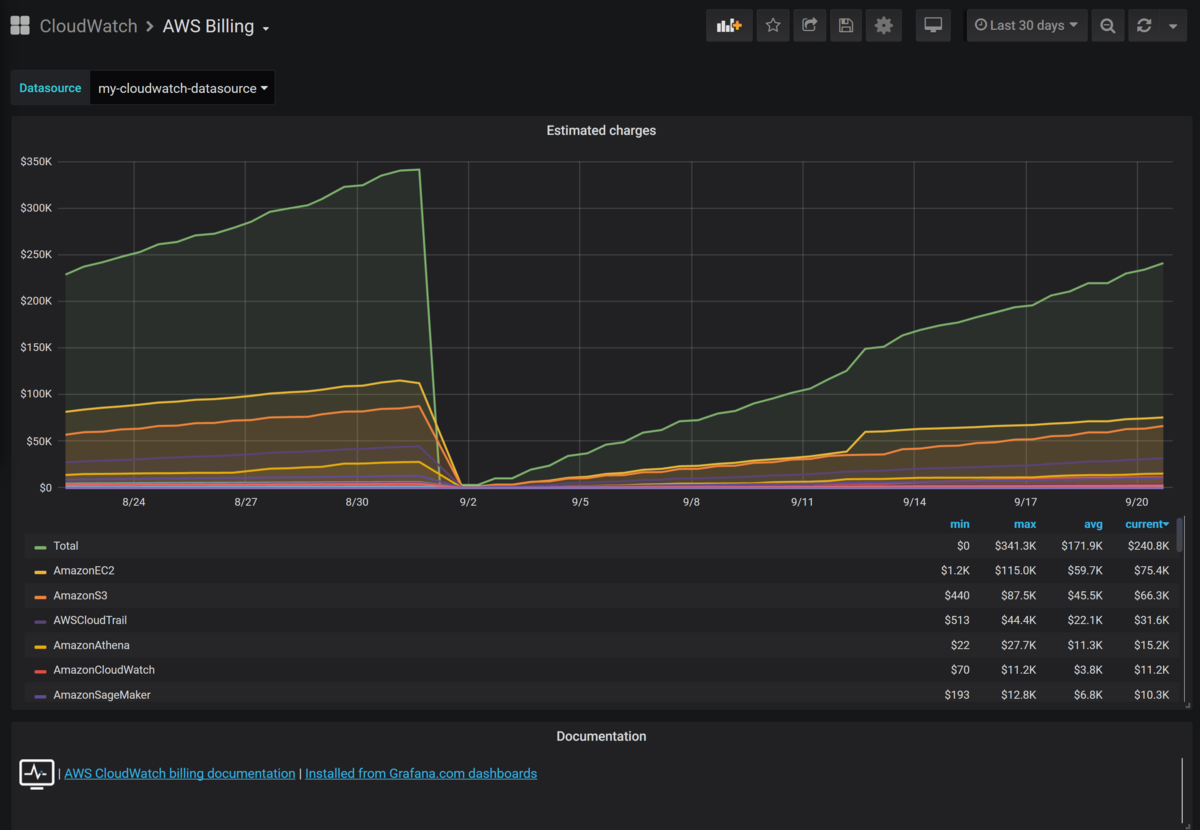
これはAWSの利用料金を表示するダッシュボードです。公開しているリポジトリには含まれていませんが、前月の利用料をサービス別に比較することができるので、利用料金が爆発した時に気がつくことが出来ます。
他にもCloudWatch Metricsの生のログを表示したり、CloudWatch Logsを表示することも可能です。
ここで紹介したダッシュボード以外にもNewRelicやDataDogといった外部サービスのメトリクスやElasticserchやLokiなどのミドルウェアとも連携することができます。詳しくは公式ドキュメントをご参照ください。
まとめ
GrafanaとPrometheusを使ったモニタリングについて紹介しました。今回はdocker-composeを利用したサンプルの実行でしたが、本番環境で運用する場合は高可用性やスケール性について考慮する必要があります。
実践的なモニタリングの知識に関しては入門監視が基礎的なところからアンチパターンまで学べるのでとてもおすすめです。
また、弊社では先日にWebプロダクト開発学習ロードマップのProgate Journeyをリリースしました。モニタリングに関しての前後の知識を学ぶことが出来ます。興味がある人は一読をおすすめします。
次は hrkw00 さんが flow.js のバージョンアップデートをした話 をするそうです、ご期待ください!